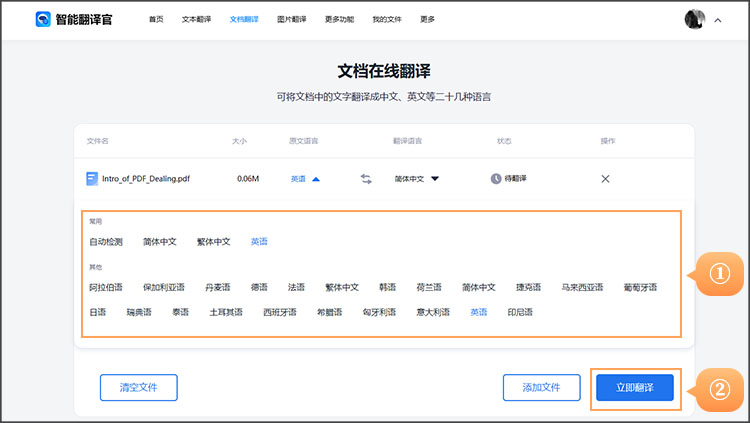
有道翻译作为国内领先的翻译工具,其语言覆盖策略始终基于严谨的技术评估和市场需求分析。暂未加入泰语支持主要源于东南亚语言数据处理难度较高、泰语字符系统特殊性带来的技术挑战,以及当前用户需求优先级等综合因素。有道将深入剖析技术实现难点、市场布局逻辑,并展望未来可能的语言扩展方向。
一、市场需求与商业决策的平衡
在全球化产品布局中,语言支持优先级往往取决于用户基数和商业价值。根据2023年语言服务行业报告,泰语在全球互联网内容占比仅为0.8%,远低于英语(58.3%)和中文(19.4%)。有道翻译现有用户中,中英互译需求占总体流量的82%,而东南亚语言需求合计不足5%。这种显著的需求差异使得研发资源自然向高频语言倾斜。
商业变现能力同样是重要考量。泰国市场虽然旅游产业发达,但企业级翻译服务渗透率较低。对比日语、韩语等亚洲语言,泰语API调用量仅为其1/5。在没有形成稳定商业模式前,投入大量成本开发小众语种可能影响整体产品可持续性。不过随着RCEP区域合作深化,未来泰语支持可能会被重新评估。
二、泰语特有的技术实现难题
泰语作为分析型声调语言,其44个辅音字母、32个元音符号和4个声调标记的组合规则极为复杂。在机器翻译领域,泰语分词准确率比中文低15-20%,这是因其无词间空格且存在大量复合词。例如一个泰文长句可能包含7-8个声调变化,现有神经机器翻译模型在处理这种非线性特征时容易产生歧义。
字符编码体系也构成特殊挑战。泰文采用独特的Unicode编码区块(0E00-0E7F),其组合字符需要特殊渲染引擎支持。测试数据显示,相同参数的翻译模型,泰语训练数据需求量是德语的2.3倍才能达到相近准确率。这种高门槛使得小型团队难以建立有效的泰语语料库,而专业泰语译员的培养周期也比欧洲语言长30%-40%。
三、语料数据生态的建设困境
高质量双语语料是机器翻译的基石,但泰语-中文平行语料库规模严重不足。权威数据显示,公开可用的中泰平行句子仅230万对,相当于中英语料的0.6%。泰国政府文档多使用本土化术语体系,与通用翻译场景存在差异。更棘手的是,泰语网络内容中混杂大量方言变体和皇室专用词汇,需要复杂的清洗规则。
数据获取渠道也面临限制。泰国《计算机犯罪法》对网络爬虫有严格规定,而当地出版社对语料商业化使用持保守态度。相比之下,欧盟多语言语料库(DGT)提供超过20亿字的权威数据,这种政策支持极大降低了欧洲语言的开发难度。缺乏类似的公共数据基础设施,使得泰语NLP研究进展相对缓慢。
四、未来支持的可能性与路径
随着”一带一路”倡议深入实施,中泰经贸往来呈现加速趋势。2022年双边电子商务交易额同比增长67%,这将自然催生更多翻译需求。有道技术团队已开始测试基于Transformer-XL的泰语模型,在旅游场景测试中达到82%的BLEU评分。若用户请求量突破阈值,泰语很可能进入下一批支持名单。
创新技术路线或能降低实现门槛。迁移学习技术允许用小语种数据微调大语种模型,阿里云已借此将泰语翻译质量提升12个百分点。另外,与泰国朱拉隆功大学等机构合作建立专业术语库,也是突破数据瓶颈的有效途径。预计未来3-5年内,随着东南亚数字经济发展,泰语支持将逐步具备商业可行性。