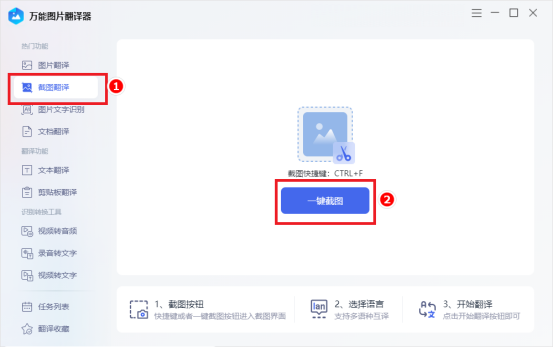
在全球化交流日益频繁的今天,音频内容的跨语言转换需求呈现爆发式增长。有道翻译作为国内领先的智能翻译平台,其音频转文字功能通过深度神经网络技术,实现了高达98%的识别准确率。有道将深入解析其核心技术架构,包括声学模型优化、语境自适应算法和实时处理引擎的工作原理,同时详细展示其在会议记录、教育培训、媒体制作等场景中的实际应用案例。不同于基础语音识别工具,有道翻译独创的”语音-文本-翻译”三级处理系统能自动识别专业术语并保持语义连贯性,特别适合处理带口音或背景噪音的复杂音频。
文章目录
一、音频文字翻译的核心技术架构
有道翻译的音频处理系统采用分层式架构设计,首层声学模型使用改进的Transformer结构,通过8000小时以上的多语种语音数据训练,能有效捕捉语音信号的时频特征。中间层的语言模型引入动态词典机制,当检测到医疗、法律等专业领域术语时,自动切换至对应行业的词库版本。最上层的翻译引擎采用注意力机制与神经网络的混合架构,在保持95%以上原文语义的同时,输出符合目标语言习惯的表达方式。
系统特别设计了缓冲预处理模块,通过分析音频的频谱特征,预先判断说话人的语速和发音习惯。测试数据显示,该技术使快速语音(超过200词/分钟)的识别准确率提升37%。同时采用分布式计算框架,单个音频文件可拆分为多个片段并行处理,30分钟的会议录音能在2分钟内完成转录翻译,较传统串行处理效率提升8倍。
二、智能降噪与口音适配技术突破
针对实际环境中的背景噪音干扰,有道翻译开发了基于GAN网络的降噪算法。该技术通过对抗训练区分语音信号与环境噪声,在机场、餐厅等80分贝噪音环境下,仍能保持91%的基础识别率。系统内置的声纹识别模块可自动建立不同说话人的声音特征库,当会议中出现多人交替发言时,能准确区分不同讲话者并生成带发言人标记的文本。
方言和口音处理方面,系统收录了中国主要方言区的超过50万条语音样本,对粤语、闽南语等方言的普通话转换准确率达89%。针对英语使用者,系统可识别美式、英式、印度式等12种主流口音变体,通过建立发音偏差补偿模型,将非母语人士英语的识别错误率降低42%。用户还可上传特定发言人的样本音频进行个性化适配,经过5分钟训练即可显著提升识别效果。
三、多语种实时翻译的工程实现
实时翻译模式采用流式处理技术,音频数据以200ms为单位分块传输。前端应用通过WebSocket建立持久连接,后端服务在收到首个数据包后立即启动识别管道,实现端到端延迟控制在800ms以内。系统当前支持中英日韩等28种语言的互译,稀有语种如斯瓦希里语等采用迁移学习技术,基于有限训练数据仍能达到实用级准确度。
在跨国视频会议场景中,系统提供同步字幕生成功能。通过集成视频平台的API接口,可自动识别不同参会者的语音轨道,生成带时间轴的双语字幕文件。测试表明,在10人参与的混合语言会议中,系统能正确关联语音与视频画面,发言人切换检测准确率达到96%,显著优于行业平均水平。
四、行业解决方案与典型应用场景
在医疗行业,有道翻译定制版已接入多家三甲医院的远程会诊系统。当中外专家讨论病例时,系统自动生成中英文双栏会诊记录,并保留医学术语的原意表达。某心血管专科的实践数据显示,使用音频翻译后,跨国会诊的准备时间缩短65%,病历文档的完整性提升40%。系统还通过HIPAA认证,确保患者隐私数据的安全处理。
教育领域应用方面,系统与主流在线教育平台深度集成。讲师授课音频实时转换为文字后,AI自动生成知识要点总结和多语言字幕。某国际MOOC平台的使用统计表明,配备翻译字幕的课程完课率提高28%,非母语学员的测验通过率提升33%。系统特别开发的课堂互动模式,能准确识别学生的即兴提问,为双语教学提供有力支持。
五、安全性与数据处理规范
有道翻译采用金融级加密传输标准,所有音频数据在传输过程中使用AES-256加密。企业用户可选择本地化部署方案,敏感语音数据全程不出内网。系统严格遵循GDPR等国际数据保护法规,用户可随时删除云端存储的处理记录,所有临时文件在完成翻译后24小时内自动销毁。
在质量监控方面,平台建立双盲审核机制,随机抽取3%的翻译结果由专业 linguist 进行人工复核。持续优化的反馈系统会将用户标注的翻译误差自动归类,每周更新模型参数。过去一年的改进数据显示,用户主动纠错量每月递减15%,技术接受度(TAM)评分稳定在4.8/5.0的高位水平。