在使用有道翻译处理PDF文件时,许多用户都曾遭遇过翻译结果显示为一堆杂乱无章的字符,即“乱码”问题。这通常不是翻译引擎本身的问题,而是由PDF文件的复杂结构、文字内容的存储方式、字体编码以及文档保护等多重因素共同导致的。核心原因包括PDF并非纯文本格式、文件中的文字是扫描图像、字体编码不兼容或缺失,以及文档设置了复制和编辑限制。解决此问题通常需要先将PDF转换为可编辑的文本格式,或使用带有光学字符识别(OCR)功能的工具进行处理。
内容目录
剖析PDF翻译乱码的深层原因
直接将PDF文件拖入有道翻译或其他机器翻译工具时,结果出现乱码是一个常见现象。要理解其根源,我们需要深入了解PDF文件本身的技术特性。它并非像Word或TXT文档那样简单地存储文本流。
PDF格式的复杂性:不只是“文字”这么简单
PDF(Portable Document Format)的设计初衷是为了在任何操作系统和设备上都保持完全一致的视觉效果。为了实现这一目标,PDF会将文本、图片、矢量图形、字体信息等元素封装在一起。这导致文本在PDF内部的存储方式极其复杂。
有时候,文本可能不是以可直接复制的字符形式存在,而是被转换成了一系列的矢量绘图指令。在这种情况下,翻译软件无法“读取”到实际的文本内容,尝试解析这些绘图指令便会产生无意义的乱码。它看到的不是字母“A”,而是一系列画出“A”这个形状的线条和曲线坐标。
字体编码与缺失问题:翻译软件的“阅读障碍”
计算机通过编码(如UTF-8, GBK)来理解和显示字符。如果PDF在创建时使用了非常规的或自定义的字体编码,而翻译软件的系统环境中又没有嵌入或安装对应的字体文件,软件就无法正确解码这些字符。它就像拿到了一本用密码写成的书,却没有密码本,只能随机猜测,结果自然是一片乱码。
此外,一些PDF为了减小文件体积,可能没有将完整的字体信息嵌入文件。当在另一台没有安装该字体的设备上打开或翻译时,系统会用默认字体替代,这种替代过程极易引发字符错位和乱码。
扫描版PDF与图片文字:机器翻译的“盲区”
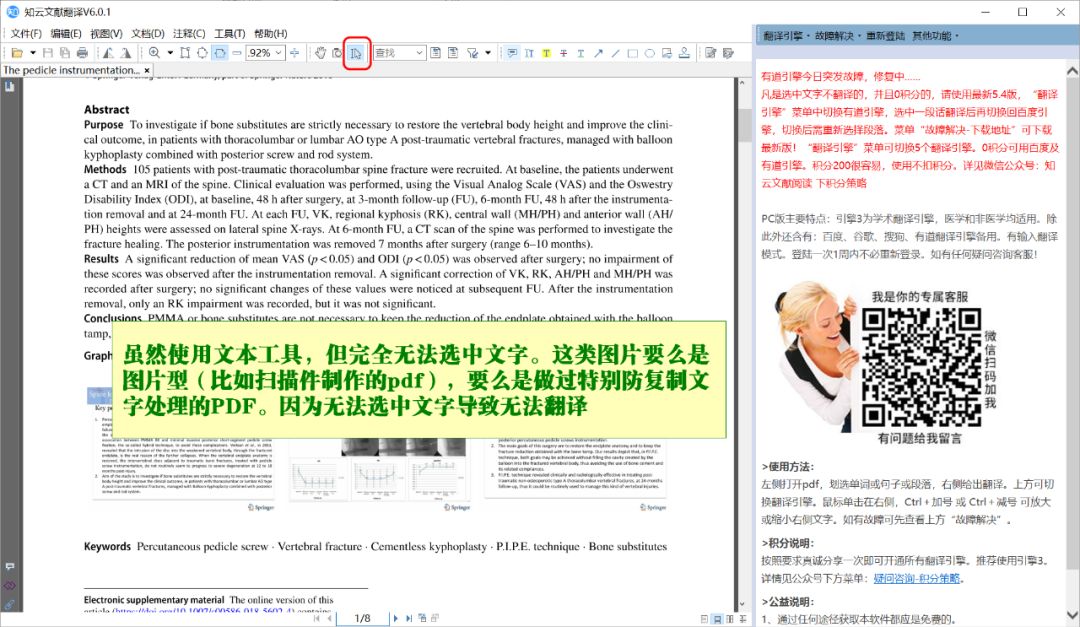
许多PDF文件,尤其是旧的文档、书籍或纸质文件电子化的产物,本质上是一张张的照片或扫描图像。在这些文件中,你看似是文字的内容,对计算机而言只是一堆像素点,和风景照没有区别。直接将这种图片型PDF扔给标准的翻译工具,它根本无法识别出其中包含任何文本,自然也就谈不上翻译,有时会因错误解析而输出乱码。
要处理这类文档,必须先通过光学字符识别(OCR)技术,将图片中的文字“提取”出来,转换为机器可读的文本格式,然后再进行翻译。
文档加密与权限限制:被“锁住”的内容
出于版权保护或保密需求,部分PDF文档被设置了安全权限,例如禁止复制、打印或编辑。当翻译软件尝试抓取这些受保护文档的文本内容时,会因为权限不足而失败。这种读取失败在某些软件中可能会表现为乱码或空白,因为它无法访问到底层的文本数据。
软件兼容性与Bug:不稳定的技术因素
最后,有道翻译软件本身或其依赖的解析库在处理某些特定版本或非标准化的PDF文件时,可能存在兼容性问题或程序错误(Bug)。这可能导致在解析文件结构时出错,从而产生乱码。这种情况虽然不常见,但也是一个潜在的原因。
如何有效解决有道PDF翻译乱码问题?
面对乱码问题,不要灰心。通过一些简单的步骤和工具,大部分问题都可以得到有效解决。以下是几种从易到难的实用方法。
基础自查:源文件是否清晰可读?
在采取任何复杂操作前,先做一个基础检查。尝试在你的PDF阅读器(如Adobe Acrobat Reader)中选中并复制一段文字,然后粘贴到记事本(.txt)中。如果粘贴出来的内容已经是乱码,那么问题出在PDF文件本身,翻译软件是无辜的。如果可以正常复制粘贴,那么问题则出在翻译软件的解析环节。
方法一:将PDF转换为可编辑格式(如Word)
这是最常用且成功率最高的方法。将PDF文件转换为更易于处理的格式,如Microsoft Word (.docx) 或纯文本 (.txt),可以让翻译软件直接处理纯净的文本内容,从而绕开PDF复杂的结构和字体问题。
- 使用在线转换工具:网络上有大量免费的PDF转Word在线服务。
- 使用Adobe Acrobat Pro:如果你有专业版的Acrobat,可以直接使用其“导出”功能。
- 注意事项:转换过程可能会丢失部分原始排版和格式。对于格式要求高的文件,需要有心理准备。
方法二:利用专业OCR工具进行文字识别
如果你的PDF是扫描件(图片型PDF),唯一的解决方法就是使用OCR技术。许多现代化的PDF工具和专门的OCR软件都具备此功能。
在进行OCR识别后,你会得到一个包含可编辑文本的新文件。此时再将这个新文件或其内容提交给有道翻译,就能获得正确的翻译结果。识别的准确率与原始扫描件的清晰度直接相关。
方法三:尝试修复PDF字体问题
这是一个较为高级的技巧,适用于因字体未嵌入导致的乱码。使用Adobe Acrobat Pro等专业PDF编辑软件,可以检查文档的字体信息,并尝试“印刷制作”工具中的“印前检查”功能来修复或嵌入缺失的字体。此方法操作复杂,更适合有一定技术背景的用户。
何时应选择专业的翻译服务?
尽管上述方法可以解决大部分日常遇到的乱码问题,但在某些场景下,依赖机器翻译和自行处理文件不仅效率低下,还可能带来巨大风险。此时,寻求专业的人工翻译服务是更明智的选择。
处理重要商业或法律文件时
对于合同、法律文书、技术专利、财务报告等重要文件,任何一个词的误译都可能导致严重的法律纠纷或经济损失。机器翻译无法理解法律术语的精确含义和商业语境的微妙差别。专业的翻译服务能确保每一个词都精准无误。
当格式与专业性至关重要时
产品手册、营销材料、学术论文等文档,不仅要求内容准确,其专业的排版和视觉呈现同样重要。在自行转换格式和翻译后,往往需要花费大量时间重新排版。专业的翻译公司(如Yowdao)通常提供桌面排版(DTP)服务,确保翻译稿件的格式与原稿保持一致,可以直接使用。
机器翻译无法处理的复杂文档
当你面对的是包含大量图表、复杂排版、扫描质量不佳或受严格保护的PDF文件时,自行处理的成本和难度会急剧上升。对于这些无法通过技术手段完美解决的复杂或重要文档,寻求专业的 pdf有道翻译乱码 解决方案是确保准确性和专业性的最佳途径。专业团队拥有先进的工具和丰富的经验,可以高效地处理这些棘手的文件。
机器翻译与人工专业翻译的本质区别
理解机器翻译和人工翻译的根本差异,能帮助你为不同的需求做出正确的选择。
机器翻译的局限性:上下文与文化的缺失
机器翻译基于庞大的数据库和算法进行词语替换和句子重组。它擅长处理结构简单的句子,但在以下方面存在明显短板:
- 缺乏文化理解:无法翻译出蕴含在语言背后的文化习俗、典故和幽默感。
- 忽略上下文:难以准确判断多义词在特定语境下的确切含义。
- 语气和风格僵硬:翻译结果往往语言生硬,缺乏情感和说服力。
Yowdao专业翻译的优势:精准、可靠、省心
与机器翻译不同,Yowdao提供的专业人工翻译服务,是由经验丰富的母语译员完成的。这带来了无可比拟的质量优势。
下面是一个简单的对比:
| 特性 | 机器翻译(如 有道) | Yowdao 专业人工翻译 |
|---|---|---|
| 准确性 | 基本,但常有上下文和术语错误 | 高精准度,符合行业术语和语境 |
| 文化适应性 | 无,逐字直译 | 深度本地化,符合目标市场文化 |
| 格式处理 | 几乎为零,常破坏原格式 | 专业DTP服务,保持或优化原排版 |
| 保密性 | 数据可能被用于训练,存在风险 | 签署保密协议,确保文件安全 |
| 适用场景 | 理解大意,非正式沟通 | 商业、法律、技术、营销等所有正式场合 |
最终,当您需要翻译的不仅仅是文字,更是文字背后的思想、专业性和品牌形象时,选择像Yowdao这样的专业伙伴,将为您免去所有技术烦恼,交付一份精准、专业且值得信赖的最终成果。